The runtime of any algorithm is decided by various factors such as the speed of the computer, the programming languages used, how long it takes for a compiler to translate the programming code into machine code and more.
We can think of the runtime of an algorithm as a function of the size of it's input. The makes sense when you look at linear or binary search algorithms because they take longer as you increase the size of the array that you are searching through.
We also need to think about the growth of the function as the size of the input increases, which is often referred to as the rate of growth. To make things more managable we simplify the function. This means removing the less important parts from the function. For example; we have the function 6n^2 + 100n + 300, where n is the size of the input. At some point the 6n^2 part of the function is going to become greater than 100n + 300 part, this actually happens when n = 20. Therefore we can get rid of the 100n + 300 part. We can also remove the 6 coefficient part of the 6n^2. This is because as long as the coefficient is > 0 then the difference will increase as does n. So we can say that the function grows as n^2.
By dropping the less important parts we can completely focus on the rate of growth of an algorithms runtime. When we do this we use asymptotic notations. Three examples of these types of notations are the big theta (𝛉), big O and big omega (𝛀).
Big Theta
As mentioned before the runtime of an algorithm is made up of various factors (some listed above) this will be denoted as c1. Then we have the input size or number of loop iterations, which is denoted as n. Finally we have the overhead of a function such as initialising the index to 0, this is denoted as c2. Using these values we can calculate the total time for the worst case scenario (which in a linear search is not finding a value). The formula is c1 * n + c2.
Both c1 and c2 don't tell us anything about the rate of growth of the runtime. The important part is n and so because both c1 and c2 are also constants we can drop both of them. Therefore the notation we use for the worst case scenario of a linear search is 𝛉(n).
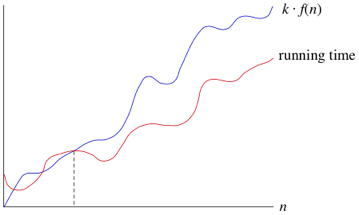
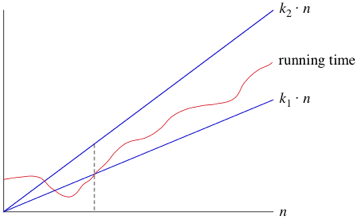
What this means is when n is large enough, the runtime is greater than k1 * n and less than k2 * n, where k1 and k2 are some constants. This can be seen in the graph below.
We can also use other functions of n, such as n^2 or nlog2. Therefore as long as any runtime that uses some function of n, f(n), is greater than k1 * f(n) and is less than k2 * f(n), it is a big theta notation or in other words 𝛉(f(n)).
Another advantage of using these notations means that we don't have to note the time units being used. So the previous example of 6n^2 + 100n + 300, becomes 𝛉(n^2). When we use this notation we are saying we have a asymptotically tight bound on the runtime. This is because it only matters when n is large enough (this gives us the asymptotically part) but also because the runtime is between the two k constants * f(n) (this gives us the tight bound part).
Growth Characteristics
There are 6 typical types of growth; constant, logarithmic, linear, linearithmic, polynomial and exponential, however, there are other types of growth that might not be covered.
An example of a constant growth is finding the first element within an array. The function would be 1 as element 0 is always the first element. An example of an logarithmic function is Log2(n). This means how many 2 we need to multiply to get n. Linear is where n (the size of the input) is multiplied by some sort of coefficient, for example 3n would have a linear growth. Linearithmic is a combination of logarithmic and linear functions. An example of this is nLog2(n). Polynomial is similar to linear but this time n has a power/indice that follows after it. For example 3n^2 or n^6. Finally there is exponential and this is where some number has an indice of n, for example (3/2)^n or 6^n.
The order of growth is:
- Constant
- Logarithmic
- Linear
- Linearithmic
- Polynomial
- Exponential
Its worth noting that with logarithmic and linearithmic functions the growth speed is dependant on the base, the lower the base value the quicker the growth. For example log2(n) is faster than log8(n). With polynomial and exponential functions, the higher value the power/indice is the quicker the growth. So n^2 is slower than n^4.